Note
This tutorial was generated from a Jupyter notebook that can be downloaded here. If you’d like to reproduce the results in the notebook, or make changes to the code, we recommend downloading this notebook and running it with Jupyter as certain cells (mostly those that change plot styles) are excluded from the tutorials.
Using the Source Class
In this tutorial, we’ll take an in-depth look at the LEGWORK Source class and its various methods that you can use to your advantage.
Let’s start by importing the source module of LEGWORK and some other common packages.
[2]:
from legwork import source, utils, visualisation
import numpy as np
import astropy.units as u
from astropy.coordinates import SkyCoord
import matplotlib.pyplot as plt
Instantiating a Source Class
The Source class gives you access to the majority of the functionality of LEGWORK from one simple class. Once a collection of sources is instantiated in this class you can calculate their strains and signal-to-noise ratios, evolve them over time and visualise their distributions or plot them on the LISA sensitivity curve.
Basic input
Let’s start by creating a random collection of possible LISA sources.
[4]:
# create a random collection of sources
n_values = 1500
m_1 = np.random.uniform(0, 10, n_values) * u.Msun
m_2 = np.random.uniform(0, 10, n_values) * u.Msun
dist = np.random.normal(8, 1.5, n_values) * u.kpc
f_orb = 10**(-5 * np.random.power(3, n_values)) * u.Hz
ecc = 1 - np.random.power(3, n_values)
We can instantiate a Source class using these random sources as follows:
[5]:
sources = source.Source(m_1=m_1, m_2=m_2, ecc=ecc, dist=dist, f_orb=f_orb, gw_lum_tol=0.05, stat_tol=1e-2,
interpolate_g=True, interpolate_sc=True,
sc_params={
"instrument": "LISA",
"custom_psd": None,
"t_obs": 4 * u.yr,
"L": 2.5e9 * u.m,
"approximate_R": False,
"confusion_noise": 'robson19'
})
There’s a couple of things to focus on here. The masses, eccentricity and distance are all required for every source. However, you can choose to either supply the orbital frequency, f_orb, or the semi-major axis, a. Whichever you supply, the other will be immediately calculating using Kepler’s third law and can be accessed immediately.
[6]:
# the semi-major axes have been calculated
sources.a
[6]:
Gravitational Wave Luminosity Tolerance
Next, we set the tolerance for the accuracy of the gravitational wave luminosity, gw_lum_tol, to 5%. This tolerance is used for two calculations:
finding the transition between “circular” and “eccentric” binaries
determining the number of harmonics required to capture the entire signal of a binary
Since, a more stringent tolerance will require binaries to be considered eccentric at lower eccentricities (and thus consider more than the \(n = 2\) harmonic), whilst also require computing more harmonics in order to get the luminosity equal to the true value within the tolerance.
Let’s see how this works in practice.
[7]:
# start with a tolerance of 5%
sources.update_gw_lum_tol(gw_lum_tol=0.05)
print("Eccentricity at which we consider sources to be eccentric is {:.3}".format(sources.ecc_tol),
"for a tolerance of {:.2}".format(sources._gw_lum_tol))
# change to a tolerance of 1%
sources.update_gw_lum_tol(gw_lum_tol=0.01)
print("Eccentricity at which we consider sources to be eccentric is {:.3}".format(sources.ecc_tol),
"for a tolerance of {:.2}".format(sources._gw_lum_tol))
Eccentricity at which we consider sources to be eccentric is 0.0667 for a tolerance of 0.05
Eccentricity at which we consider sources to be eccentric is 0.0295 for a tolerance of 0.01
Warning
if you need to change the gw_lum_tol of a Source class then it is critical that you do so using the legwork.source.Source.update_gw_lum_tol() (example above) rather than changing Source._gw_lum_tol directly. This is because the function also makes sure that ecc_tol and harmonics_required function are recalculated and kept in sync.
We can also plot the number of required harmonics for each eccentricity for different tolerances and see that you always need a greater or equal number of harmonics for a smaller tolerance.
[8]:
fig, ax = plt.subplots()
e_range = np.linspace(0.01, 0.995, 10000)
# change to a tolerance of 1%
sources.update_gw_lum_tol(gw_lum_tol=0.01)
ax.loglog(e_range, sources.harmonics_required(e_range), lw=3, label="1% tolerance")
# reset to a tolerance of 5%
sources.update_gw_lum_tol(gw_lum_tol=0.05)
ax.loglog(e_range, sources.harmonics_required(e_range), lw=3, label="5% tolerance")
ax.legend()
ax.set_xlabel(r"$\log_{10}(e)$")
ax.set_ylabel("Harmonics needed for sum")
plt.show()
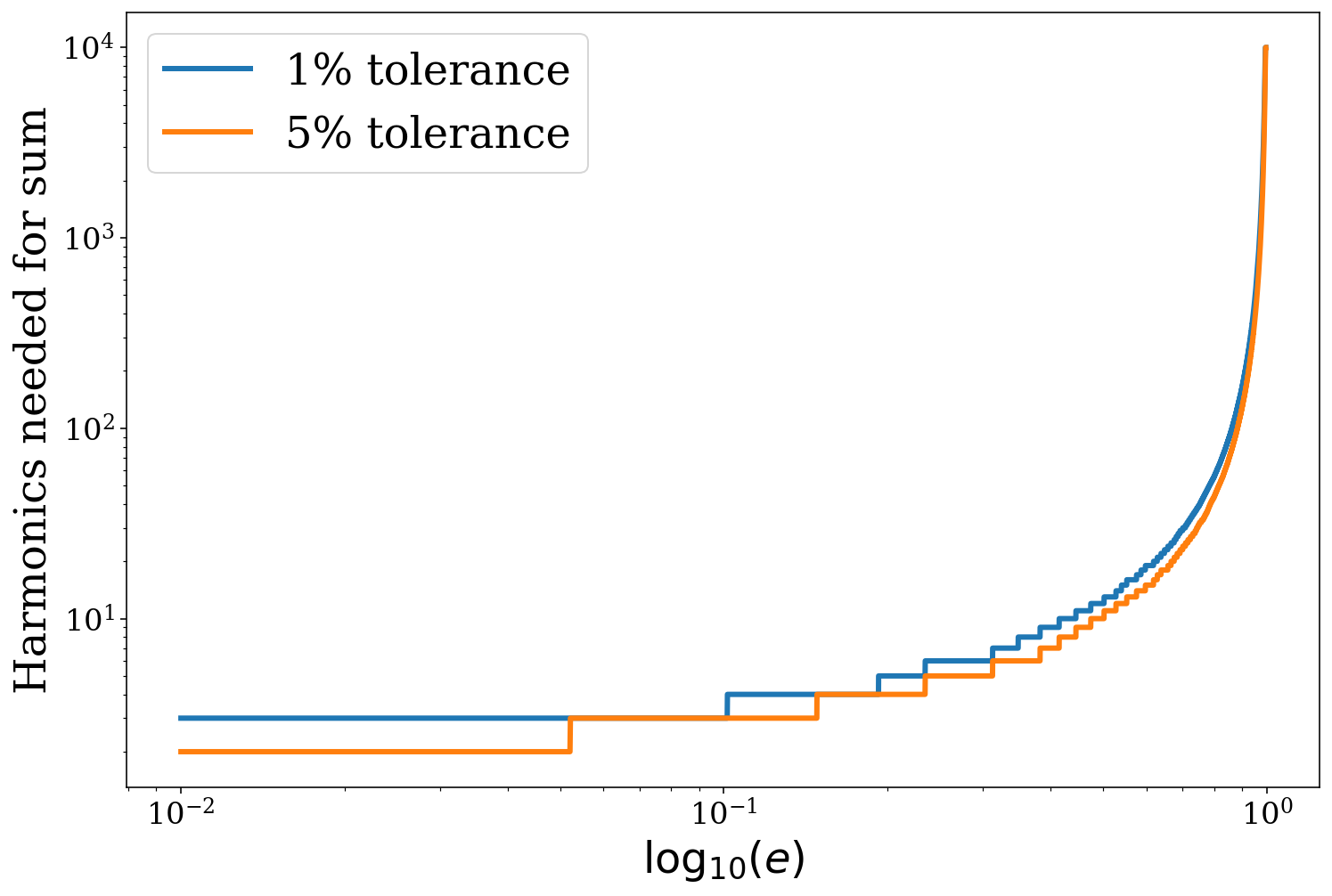
Stationary Tolerance
We also set the stationary tolerance in instantiating the class. This tolerance is used to determine which binaries are stationary in frequency space, and thus for which ones we can use the stationary approximation of the SNR. We define a binary as stationary in frequency space on the timescale of the LISA mission if the fractional change in orbital frequency, \(\Delta f_{\rm orb} / f_{\rm orb}\), is less than or equal to the tolerance.
We can see how this changes things in practice.
[9]:
# create a plot
fig, axes = plt.subplots(1, 2, figsize=(16, 8))
fig.subplots_adjust(wspace=0.3)
# use the same labels for each
labels = ["Stationary", "Evolving"]
# loop over tolerances and colours
for i, vals in enumerate([(1e-5, "Purples"), (1e-2, "Blues")]):
tol, col = vals
# adjust the tolerance
sources.stat_tol = tol
# get a mask for the stationary binaries
stat_mask = sources.get_source_mask(stationary=True)
# create a pie chart
axes[i].pie([len(stat_mask[stat_mask]), len(stat_mask[np.logical_not(stat_mask)])], labels=labels,
colors=[plt.get_cmap(col)(0.5), plt.get_cmap(col)(0.7)])
# write what the tolerance was
axes[i].set_xlabel("Stationary if "\
+ r"$\frac{\Delta f_{\rm orb}}{f_{\rm orb}} <$"\
+ "{:.3f}%".format(tol * 100))
plt.show()

\(g(n,e)\) Interpolation
Another thing to consider when creating a new source class is whether to interpolate the \(g(n,e)\) function from Peters (1963). This function is a complex combination of Bessel functions and thus is slow to compute. We therefore add the option to load in pre-computed \(g(n,e)\) values and interpolate them instead of computing the values directly. We perform this interpolation once upon class creation and use it throughout after this. The pre-computed values span 1000 values of eccentricity and 10000 harmonics and thus are accurate for \(e < 0.995\).
We can illustrate the difference in speed and results for the interpolated function vs. the real one.
[10]:
%%timeit
e_range = np.random.uniform(0.0, 0.995, 1000)
n_range = np.arange(1, 150 + 1).astype(int)
E, N = np.meshgrid(e_range, n_range)
sources.g(N, E)
89.4 ms ± 368 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
[11]:
%%timeit
e_range = np.random.uniform(0.0, 0.995, 1000)
n_range = np.arange(1, 150 + 1).astype(int)
E, N = np.meshgrid(e_range, n_range)
utils.peters_g(N, E)
1.88 s ± 18.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
You can see here that the interpolated function is roughly 500 times faster. Now let’s ensure that they are giving the same results.
[12]:
e_range = np.random.uniform(0.0, 0.9, 10)
n_range = np.arange(1, 150 + 1).astype(int)
N, E = np.meshgrid(n_range, e_range)
g_interpolated = sources.g(N, E)
g_true = utils.peters_g(N, E)
[13]:
difference = np.abs(g_true - g_interpolated)
print("The largest difference between the interpolated and true value is {:.2e}".format(np.max(difference)))
print("Whilst the average difference is {:.2e}".format(np.mean(difference)))
The largest difference between the interpolated and true value is 3.31e-09
Whilst the average difference is 9.24e-11
So the functions also give pretty much the same values. However, if you happen to have a lot of computing power and time is not a factor for you then setting interpolate_g=False will give you more accurate results.
You should also consider that if you only have a couple of sources then the time saved by avoiding computing \(g(n, e)\) would actually be less than the time it takes to interpolate. So for small populations of sources we recommend testing the runtime with interpolate_g=False to check whether it is faster.
Sensitivity Curve Interpolation
Finally, similar to the previous section, we offer the ability to interpolate the sensitivity curve. The only difference is you can also pass sc_params to update the arguments that are passed to the sensitivity curve function. This provides increased speed for large samples of sources, timesteps and harmonics but will make little difference for smaller collections of sources.
By default the SNR function (see below) will use the parameters in sc_params (e.g. the mission length or confusion noise model) when computing SNRs.
Strain and SNR calculations
Strain functions
The source class provides a convenient wrapper around the functions from the strain module and allows you to compute either the strain or characteristic strain for any number of harmonics and any subset of the sources.
Let’s try this out with the same source class instance from earlier.
[14]:
# compute h_c_n for every source for the first four harmonics
h_c_n4 = sources.get_h_c_n(harmonics=[1, 2, 3, 4])
print(h_c_n4)
[[2.58401775e-18 1.29686984e-16 1.29241567e-17 9.59145476e-19]
[2.93725038e-17 1.20593710e-16 1.16533931e-16 8.09087099e-17]
[3.52453231e-17 3.53975715e-17 7.25833584e-17 8.92173344e-17]
...
[3.69465929e-17 1.28759262e-16 1.38562269e-16 1.06034221e-16]
[3.34068827e-17 1.57002715e-16 1.38032533e-16 8.78047587e-17]
[2.07256318e-17 4.72627260e-17 6.50624416e-17 6.13288557e-17]]
Now imagine an (admittedly rather strange) scenario in which you only want to compute the strain for every other source. This is pretty easy to do!
[15]:
every_other = np.array([i % 2 == 0 for i in range(sources.n_sources)])
h_0_n = sources.get_h_0_n(harmonics=[1, 2, 3, 4], which_sources=every_other)
print("The shape of this strain array is {}".format(h_0_n.shape))
print("(since we compute the first 4 harmonics and only for every other source)")
The shape of this strain array is (750, 4)
(since we compute the first 4 harmonics and only for every other source)
This may seem a little contrived but we could also use this to isolate the circular sources and compute them separately (since then we needn’t bother with any harmonic except \(n = 2\)).
[16]:
circular = sources.get_source_mask(circular=True)
h_c_n = sources.get_h_0_n(harmonics=2, which_sources=circular)
print("The shape of this characteristic strain array is {}".format(h_c_n.shape)),
print("(since we compute only the n=2 harmonic and only for circular sources)")
The shape of this characteristic strain array is (299, 1)
(since we compute only the n=2 harmonic and only for circular sources)
Signal-to-Noise Ratio
The snr module of LEGWORK contains four functions for calculating the SNR depending on whether a binary is stationary/evolving and circular/eccentric using various approximations. However, the source class takes cares of sending the right binaries to the right functions and all you have to do is set the gw_lum_tol and stat_tol when instantiating the class (see above) and then call legwork.source.Source.get_snr().
This splits the sources into (up to) 4 subsets and calculates their SNRs before recollecting them and storing the result in source.snr.
Let’s try this out. Note that we run with verbose=True here so that you can see the size of subpopulation.
[17]:
snr_4 = sources.get_snr(verbose=True)
Calculating SNR for 1500 sources
0 sources have already merged
1359 sources are stationary
272 sources are stationary and circular
1087 sources are stationary and eccentric
141 sources are evolving
27 sources are evolving and circular
114 sources are evolving and eccentric
We can also adjust the length of the LISA mission to see how this affects the SNR. It is also important in general to update the sensitivity curve parameters for the interpolation so that the interpolated sensitivity curve matches the updated mission length. LEGWORK handles this for get_snr as long as reinterpolate_sc=True.
[18]:
snr_10 = sources.get_snr(t_obs=10 * u.yr, verbose=True)
Calculating SNR for 1500 sources
0 sources have already merged
1333 sources are stationary
268 sources are stationary and circular
1065 sources are stationary and eccentric
167 sources are evolving
31 sources are evolving and circular
136 sources are evolving and eccentric
Note that you can see that the number of stationary binaries has decreased slightly since some binaries may just be on the cusp of no longer being stationary and extending the time means they change frequency enough to be labelled as evolving. It could be interesting to do this to see how the number of detectable binaries changes.
[19]:
n_detect_4 = len(snr_4[snr_4 > 7])
n_detect_10 = len(snr_10[snr_10 > 7])
print("{} binaries are detectable over 4 years".format(n_detect_4))
print("Whilst extending to a 10 year mission gives {}".format(n_detect_10))
651 binaries are detectable over 4 years
Whilst extending to a 10 year mission gives 651
Position-inclination-polarisation specfic sources
For some sources, you may already know the positions and this means that you can use a more specific SNR calculation (see the derivations for more details) rather than an average. Note that since this SNR calculation also considers frequency spreading due to doppler modulation from the detector orbit, the SNR will always be lower than in the fully averaged case.
We can input this when instantiating the source. For positions we use the Skycoord Class from Astropy, which allows you to specific the coordinates in any frame and it will automatically convert it to the necessary coordinates in LEGWORK.
[20]:
# redefine f_orb so all binaries are stationary (can't use position-specific snr for evolving sources)
specific_f_orb = 10**np.random.uniform(-5, -4, len(m_1)) * u.Hz
sources_specific = source.Source(m_1=m_1, m_2=m_2, f_orb=specific_f_orb, dist=dist, ecc=np.repeat(0.0, len(m_1)),
position=SkyCoord(lon=np.random.uniform(0, 2 * np.pi) * u.rad,
lat=(np.arccos(np.random.uniform(-1, 1, len(m_1))) - np.pi / 2) * u.rad,
distance=dist, frame="heliocentrictrueecliptic"),
inclination=np.arccos(np.random.uniform(0, 1, len(m_1))) * u.rad,
polarisation=np.random.uniform(0, 2 * np.pi, len(m_1)) * u.rad)
sources_specific.get_snr()
[20]:
array([8.27343716e-04, 3.77437152e-04, 2.22216119e-04, ...,
5.93935881e-04, 2.93496598e-03, 4.02022383e-05])
[21]:
sources_average = source.Source(m_1=m_1, m_2=m_2, f_orb=specific_f_orb,
dist=dist, ecc=np.repeat(0.0, len(m_1)))
sources_average.get_snr()
[21]:
array([0.00293926, 0.00163245, 0.00065018, ..., 0.00142268, 0.00728637,
0.00014893])
Let’s plot the ratio of the SNR for the two cases using the visualisation module.
[22]:
snr_ratio = sources_specific.snr / sources_average.snr
fig, ax = visualisation.plot_1D_dist(snr_ratio, bins="fd", xlabel="SNR (specific) / SNR(average)")
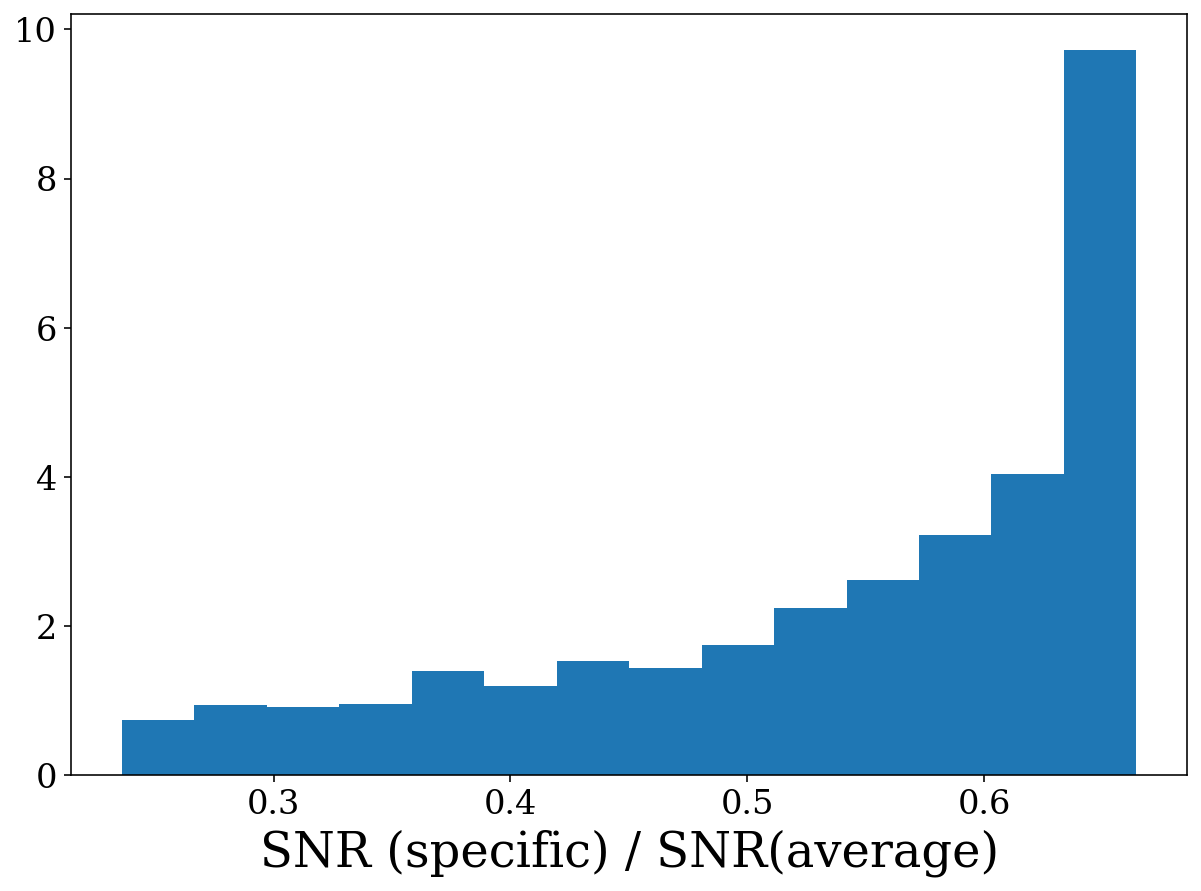
As you can see, the SNR for a specific source is always lower than for the average source. This is because the modulation reduces the strain amplitude as the smearing in frequency reduces the amount of signal build up at the true source frequency.
Visualisation
Although the visualisation model gives more freedom in honing various aspects of your plots, for general analysis the source class has two functions to quickly create plots to investigate distributions.
Parameters Distributions
The first function is legwork.source.Source.plot_source_variables() which can create either 1D or 2D distributions of any subpopulation of sources.
Let’s take it for a spin with a collection of stationary binaries.
[23]:
# create a random collection of sources
n_values = 15000
m_1 = np.random.uniform(0, 10, n_values) * u.Msun
m_2 = np.random.uniform(0, 10, n_values) * u.Msun
dist = np.random.normal(8, 1.5, n_values) * u.kpc
f_orb = 10**(np.random.normal(-5, 0.5, n_values)) * u.Hz
ecc = 1 - np.random.power(3, n_values)
sources = source.Source(m_1=m_1, m_2=m_2, ecc=ecc, dist=dist, f_orb=f_orb)
This function will let you plot any of several parameters (listed in the table below) and work out the units for the axes labels automatically based on the values in the source class.
Parameter |
Label |
|---|---|
Primary Mass |
m_1 |
Secondary Mass |
m_2 |
Chirp Mass |
m_c |
Eccentricity |
ecc |
Distance |
dist |
Orbital Frequency |
f_orb |
Gravitational Wave Frequency |
f_GW |
Semi-major Axis |
a |
Signal-to-noise Ratio |
snr |
We can start simple and just plot the orbital frequency distribution for all sources. For a 1D distribution we only need to use xstr and can leave ystr as None. The various keyword arguments are passed to legwork.visualisation.plot_1D_dist() and legwork.visualisation.plot_2D_dist(), for more info check out the Visualisation tutorial!
[24]:
fig, ax = sources.plot_source_variables(xstr="f_orb", disttype="kde", log_scale=True, linewidth=3)
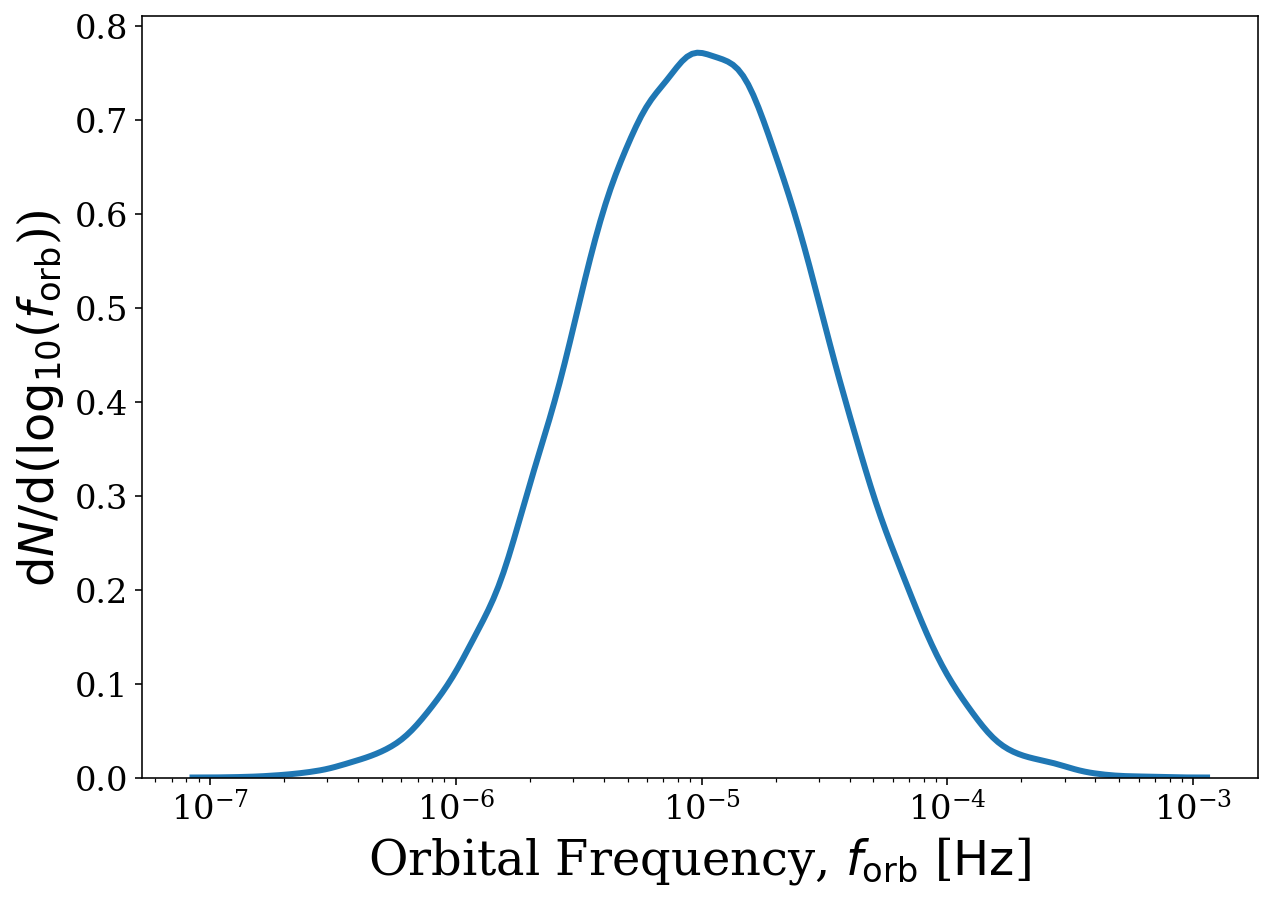
But we could also try to see how the detectable population is different from the entire population. Let’s create two frequency KDEs, one for the detectable binaries and another for all of them. For this we will use the which_sources parameter and pass a mask on the SNR.
[25]:
# calculate the SNR
snr = sources.get_snr(verbose=True)
# mask detectable binaries
detectable = snr > 7
# plot all binaries
fig, ax = sources.plot_source_variables(xstr="f_orb", disttype="kde", log_scale=True, linewidth=3,
show=False, label="all binaries")
# plot all binaries
fig, ax = sources.plot_source_variables(xstr="f_orb", disttype="kde", log_scale=True, linewidth=3, fig=fig,
ax=ax, which_sources=detectable, label="detectable binaries",
show=False)
ax.legend()
plt.show()
Calculating SNR for 15000 sources
0 sources have already merged
15000 sources are stationary
2858 sources are stationary and circular
12142 sources are stationary and eccentric
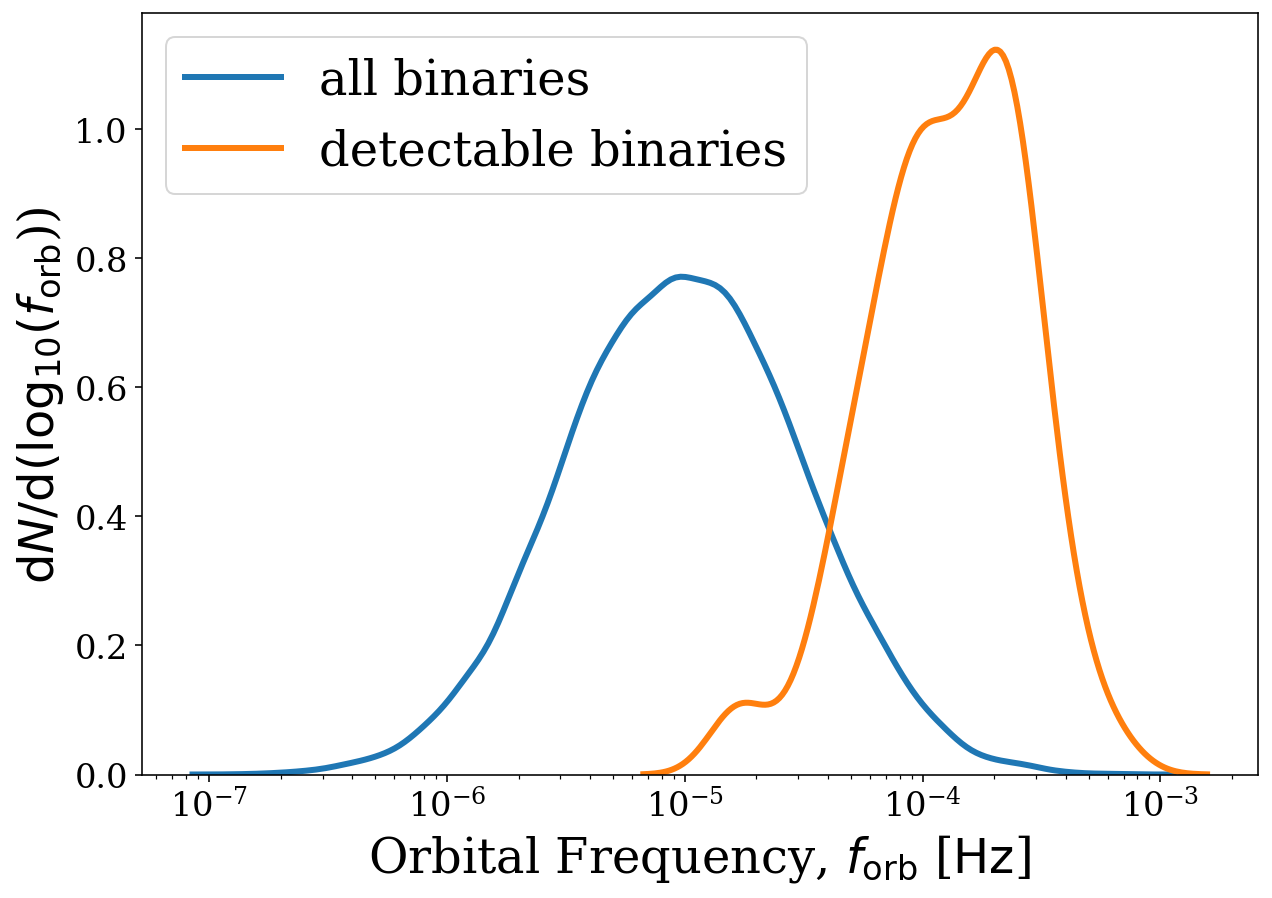
Here’s we can see that the distribution is shifted to higher frequencies for detectable binaries which makes sense since these are easier to detect.
Sources on the Sensitivity Curve
The other function is legwork.Source.source.plot_sources_on_sc() which plots all sources on the sensitivity curve.
Note
This is currently only implemented for stationary binaries. We are working on adding the same functionality for evolving binaries.
Here we set snr_cutoff=7 so that only binaries with SNR > 7 are plotted and switch the disttype to a KDE density plot.
[26]:
fig, ax = sources.plot_sources_on_sc(snr_cutoff=7, disttype="kde")

That’s all for this tutorial, be sure to check out the other ones to find other ways to keep your feet up and let us do the LEGWORK!